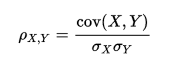Custom ML Pipeline is built using OOP programming.
In OOP, we write code in the form of objects.
The objects can store data and can also store instructions or procedures to modify that data.
Data => attributes.
Instructions pr procedures => methods.
A pipeline is a set of data processing steps connected in series, where typically, the output of one element is the input of the next one.
The element of a pipeline can be executed in parallel or in time-sliced fashion. This is useful when we require use of big data or high computing power eg: neural networks.
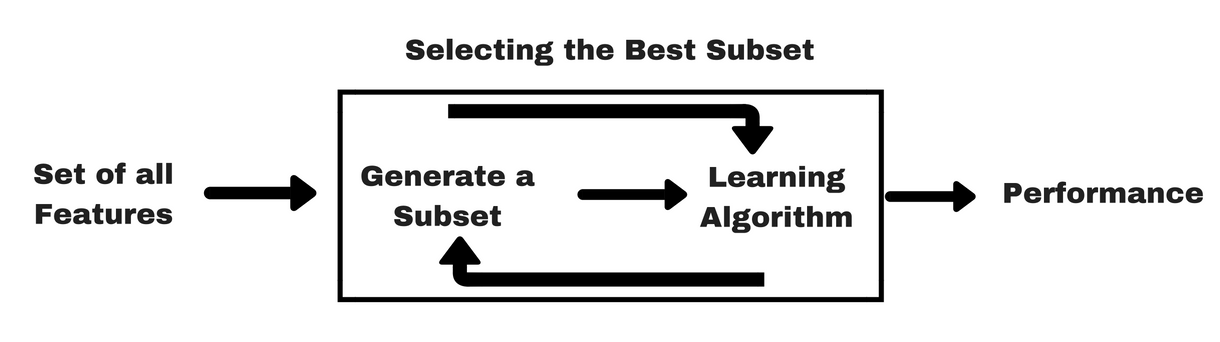
So, a custom ml pipeline is a sequence of steps, aimed at loading and transforming data, to get it ready for training or scoring where:
- We write processing steps as objects(OOP)
- We write sequence i.e pipeline as objects (OOP)
Refer: customPipelineProcessor.py
customPipelineTrain.py

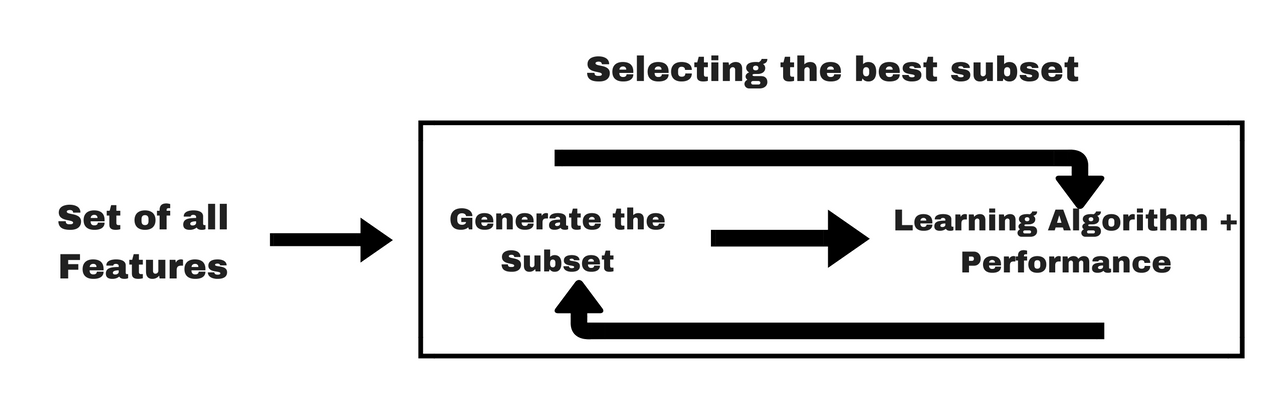
Leveraging Third party pipeline : Scikit-Learn

How is scikit-learn organized?

The characteristics of scikit-learn pipeline is such that, you can have as many transformers as you want and all of them except the last one, the last one should be a predictor.
Feature creation and Feature engineering steps as Scikit-learn Objects.
Transformers: class that have fit an transform method, it transforms data.
Use of scikit-learn base transformers
Inherit class and adjust the fit and transform methods.

In OOP, we write code in the form of objects.
The objects can store data and can also store instructions or procedures to modify that data.
Data => attributes.
Instructions pr procedures => methods.
A pipeline is a set of data processing steps connected in series, where typically, the output of one element is the input of the next one.
The element of a pipeline can be executed in parallel or in time-sliced fashion. This is useful when we require use of big data or high computing power eg: neural networks.
So, a custom ml pipeline is a sequence of steps, aimed at loading and transforming data, to get it ready for training or scoring where:
- We write processing steps as objects(OOP)
- We write sequence i.e pipeline as objects (OOP)
Refer: customPipelineProcessor.py
customPipelineTrain.py

Leveraging Third party pipeline : Scikit-Learn

How is scikit-learn organized?

The characteristics of scikit-learn pipeline is such that, you can have as many transformers as you want and all of them except the last one, the last one should be a predictor.

Feature creation and Feature engineering steps as Scikit-learn Objects.
Transformers: class that have fit an transform method, it transforms data.
Use of scikit-learn base transformers
Inherit class and adjust the fit and transform methods.

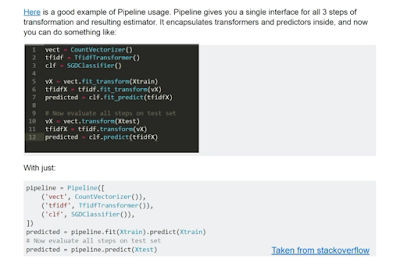
Scikit-Learn Pipeline - Code
Below
the code for the Scikit-Learn pipeline, utilising the transformers we
created in the previous lecture. Briefly, we list inside the pipeline,
the different transformers, in the order they should run. The final step
is the linear model. Right in front of the linear model, we should run
the Scaler.
You will better understand the structure of the code in the coming lectures. Briefly, we write the transformers in a script within a folder called processing. We also write a config file, where we specify the categorical and numerical variables. Bear with us and we will show you all the scripts. For now, make sure you understand well how to write a scikit-learn pipeline.
You will better understand the structure of the code in the coming lectures. Briefly, we write the transformers in a script within a folder called processing. We also write a config file, where we specify the categorical and numerical variables. Bear with us and we will show you all the scripts. For now, make sure you understand well how to write a scikit-learn pipeline.
Should feature selection be part of the pipeline?
- from sklearn.linear_model import Lasso
- from sklearn.pipeline import Pipeline
- from sklearn.preprocessing import MinMaxScaler
- from regression_model.config import config
- from regression_model.processing import preprocessors as pp
- price_pipe = Pipeline([
- ('categorical_imputer', pp.CategoricalImputer(variables = config.CATEGORICAL_VARS_WITH_NA)),
- ('numerical_inputer', pp.NumericalImputer(variables = config.NUMERICAL_VARS_WITH_NA)),
- ('temporal_variable', pp.TemporalVariableEstimator(variables=config.TEMPORAL_VARS, reference_variable=config.REFERENCE_TEMP_VAR)),
- ('rare_label_encoder', pp.RareLabelCategoricalEncoder(tol = 0.01, variables = config.CATEGORICAL_VARS)),
- ('categorical_encoder', pp.CategoricalEncoder(variables=config.CATEGORICAL_VARS)),
- ('log_transformer', pp.LogTransformer(variables = config.NUMERICALS_LOG_VARS)),
- ('drop_features', pp.DropUnecessaryFeatures(variables_to_drop = config.DROP_FEATURES)),
- ('scaler', MinMaxScaler()),
- ('Linear_model', Lasso(alpha=0.005, random_state=0))
- ])
Scikit-Learn and sklearn pipeline: Additional reading resources
- Introduction to Scikit-Learn
- Six reasons why I recommend Scikit-Learn
- Why you should learn Scikit-Learn
- Deep dive into SKlearn pipelines from Kaggle
- SKlearn pipeline tutorial from Kaggle
- Managing Machine Learning workflows with Sklearn pipelines
- A simple example of pipeline in Machine Learning using SKlearn
Resources to Improve as a Python DeveloperBecome a better python developer
We have gathered the following resources for data scientists who want to learn best practices in python programming.
- The Best of the Best Practices (BOBP) Guide for Python
- Python coding standards/best practices in Stackoverflow
- Python Best Practices for More Pythonic Code
- The Hitchhickers guide to python
- Tutorials for pycharm here and here.