Feature selection refers to a phase in which we use algorithms or procedures to choose best subset of features from all the variables/feature present in your dataset. This is the process of finding the most predictive features for the model we are trying to build.
At the beginning of feature selection process, we start with entire dataset with all the variables and by the end we end up with small set of variables that are most predictive ones.
Why do we select features ?
Simple models are easier to interpret.
Shorter training times and more importantly lesser time to score when we use less features.
Enhanced generalisation by reducing overfitting.
Easier to implement by Software engineers -> model in production.
Reduced risk of data errors during model use.
Data redundancy i.e many features provide the same information.
Why having less features is important for model deployment to production?
Smaller json messages sent over to the model.
Json messages contain only the necessary variables / inputs
Less lines of code for error handling
Error handlers need to be written for each variable/ input.
Typically we write error handlers for each and every variable we send to model.
Less information to log.
Less feature engineering code.
Variable Redundancy

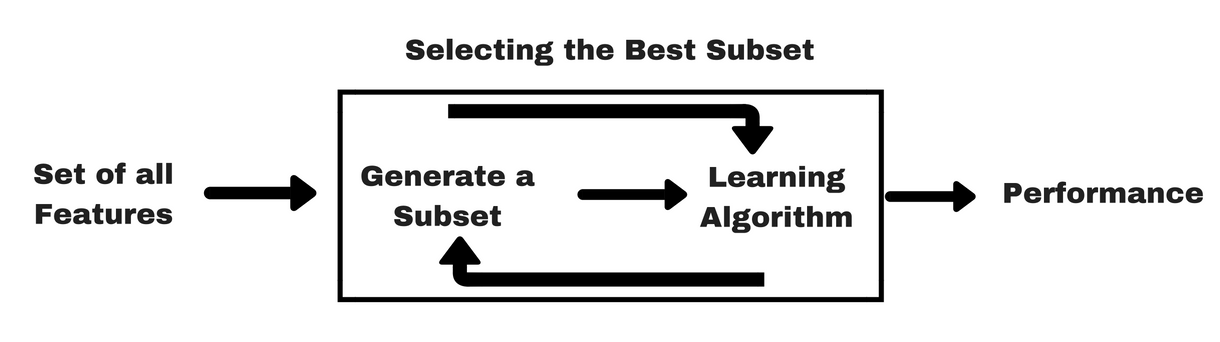
Feature Selection Methods

Filter methods




Wrapper methods

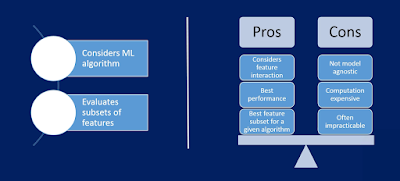
They evaluate all possible feature combinations, and only then decide which one is the best.
Embedded methods


When we deploy the model to production, its is a good practice to select the features pre hand and then deploy the model pipeline with those features, instead of deploying the pipeline for feature selection with the model.
At the beginning of feature selection process, we start with entire dataset with all the variables and by the end we end up with small set of variables that are most predictive ones.
Why do we select features ?
Simple models are easier to interpret.
Shorter training times and more importantly lesser time to score when we use less features.
Enhanced generalisation by reducing overfitting.
Easier to implement by Software engineers -> model in production.
Reduced risk of data errors during model use.
Data redundancy i.e many features provide the same information.
Why having less features is important for model deployment to production?
Smaller json messages sent over to the model.
Json messages contain only the necessary variables / inputs
Less lines of code for error handling
Error handlers need to be written for each variable/ input.
Typically we write error handlers for each and every variable we send to model.
Less information to log.
Less feature engineering code.
Variable Redundancy

Feature Selection Methods

Filter methods

Filter methods are generally used as a preprocessing step. The selection of features is independent of any machine learning algorithms. Instead, features are selected on the basis of their scores in various statistical tests for their correlation with the outcome variable. The correlation is a subjective term here. For basic guidance, you can refer to the following table for defining correlation co-efficients.

- Pearson’s Correlation: It is used as a measure for quantifying linear dependence between two continuous variables X and Y. Its value varies from -1 to +1. Pearson’s correlation is given as:
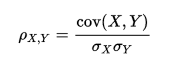
- LDA: Linear discriminant analysis is used to find a linear combination of features that characterizes or separates two or more classes (or levels) of a categorical variable.
- ANOVA: ANOVA stands for Analysis of variance. It is similar to LDA except for the fact that it is operated using one or more categorical independent features and one continuous dependent feature. It provides a statistical test of whether the means of several groups are equal or not.
- Chi-Square: It is a is a statistical test applied to the groups of categorical features to evaluate the likelihood of correlation or association between them using their frequency distribution.
One thing that should be kept in mind is that filter methods do not remove multicollinearity. So, you must deal with multicollinearity of features as well before training models for your data.

Wrapper methods
In wrapper methods, we try to use a subset of features and train a model using them. Based on the inferences that we draw from the previous model, we decide to add or remove features from your subset. The problem is essentially reduced to a search problem. These methods are usually computationally very expensive.
Some common examples of wrapper methods are forward feature selection, backward feature elimination, recursive feature elimination, etc.
- Forward Selection: Forward selection is an iterative method in which we start with having no feature in the model. In each iteration, we keep adding the feature which best improves our model till an addition of a new variable does not improve the performance of the model.
- Backward Elimination: In backward elimination, we start with all the features and removes the least significant feature at each iteration which improves the performance of the model. We repeat this until no improvement is observed on removal of features.
- Recursive Feature elimination: It is a greedy optimization algorithm which aims to find the best performing feature subset. It repeatedly creates models and keeps aside the best or the worst performing feature at each iteration. It constructs the next model with the left features until all the features are exhausted. It then ranks the features based on the order of their elimination.
One of the best ways for implementing feature selection with wrapper methods is to use Boruta package that finds the importance of a feature by creating shadow features.
It works in the following steps:
- Firstly, it adds randomness to the given data set by creating shuffled copies of all features (which are called shadow features).
- Then, it trains a random forest classifier on the extended data set and applies a feature importance measure (the default is Mean Decrease Accuracy) to evaluate the importance of each feature where higher means more important.
- At every iteration, it checks whether a real feature has a higher importance than the best of its shadow features (i.e. whether the feature has a higher Z-score than the maximum Z-score of its shadow features) and constantly removes features which are deemed highly unimportant.
- Finally, the algorithm stops either when all features get confirmed or rejected or it reaches a specified limit of random forest runs.
They evaluate all possible feature combinations, and only then decide which one is the best.

Embedded methods
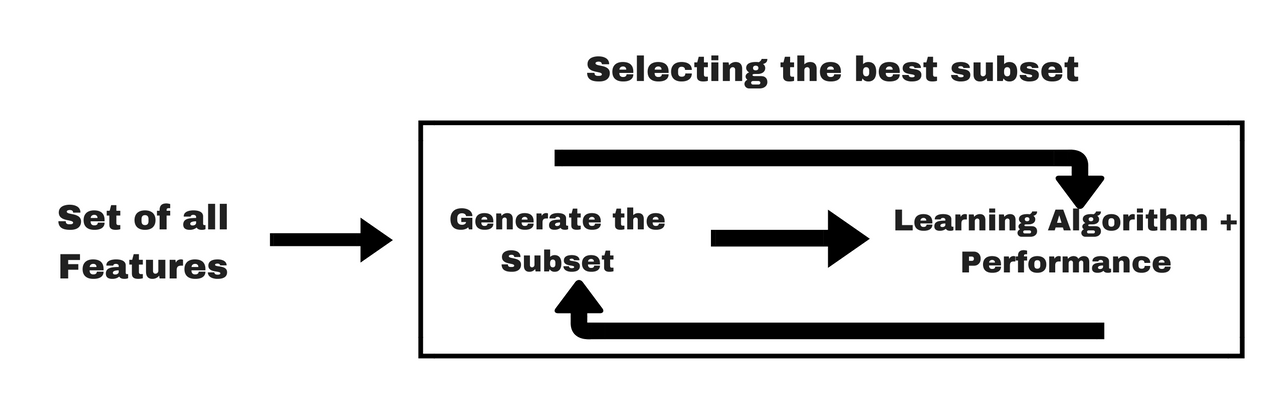
Embedded methods combine the qualities’ of filter and wrapper methods. It’s implemented by algorithms that have their own built-in feature selection methods.
Some of the most popular examples of these methods are LASSO and RIDGE regression which have inbuilt penalization functions to reduce overfitting.
- Lasso regression performs L1 regularization which adds penalty equivalent to absolute value of the magnitude of coefficients.
- Ridge regression performs L2 regularization which adds penalty equivalent to square of the magnitude of coefficients.

When we deploy the model to production, its is a good practice to select the features pre hand and then deploy the model pipeline with those features, instead of deploying the pipeline for feature selection with the model.
No comments:
Post a Comment