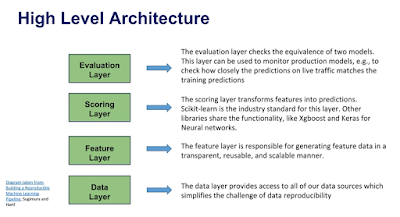
Architecture Component breakdown (ML Application)
Train by batch, predict on the fly.
Breakdown: Training Phase (done offline/ train by batch)
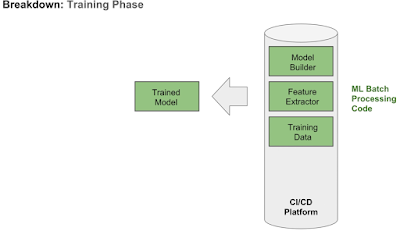
Training data: applications will be responsible for loading, processing and giving access to the training data(could be pulling data from multiple SQL or NoSQL databases, HDFS, or make API calls), perform pre processing steps to get to the format required by scikit-learn, tensorflow or another ml framework.
Feature Extractor
There will be Applications and scripts to create features, extract features(can be simple scripts or entire models itself)
Model Builder
This includes serializing and persisting models, versioning them, making sure they are in the format suitable for deployment. In python context, this would involve in packaging with a set of py files.
In Java or Scala, we might export to an mlib bundle/jar files.
All three steps will be structured into a pipeline perhaps with scikit learn or when performance is important then Apache Spark. These piplelines will be run by CI/CD platforms to automate the work.
The output is a trained model, which can be easily deployed via REST API.
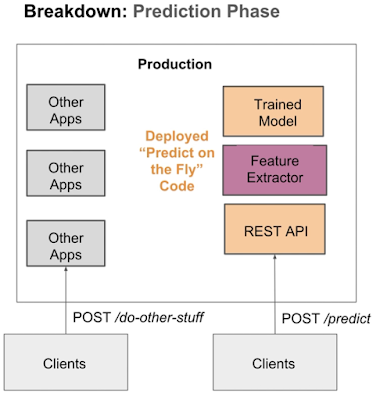
Breakdown: Prediction Phase
The model is now deployed to production to give results in real time. Requests are sent to our REST API, cleaned and prepared by the preprocessing and feature extraction code. We should mirror the code used in training as close as possible.
Prediction are given by our loaded model.
Our API can do both single and bulk predictions, where bulk predictions are subject to performance tuning and throttling.
Everything when put together, we can offline and online part of the system.
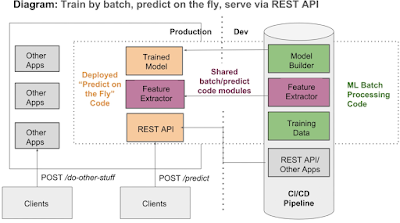
It is important to see where the code overlaps. For eg: Feature extractor(extracting features of the input given by clients to REST API as same features decided on the train time) code.
There are other components required to make the entire system running apart from application.
Entire System Diagram
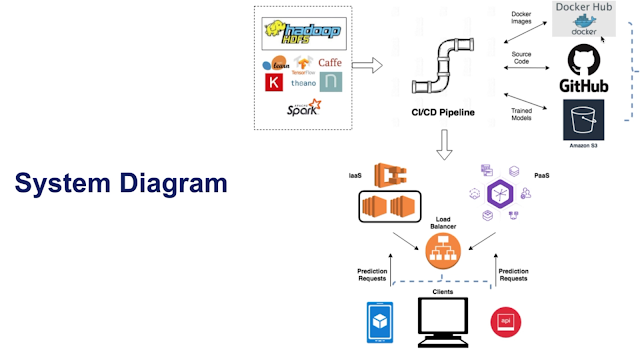
Top left is the application part with examples of tools and frameworks. CI/CD pipeline sits in the middle. Our application code can be converted into docker images and stored in image registery such as docker hub or AWS Elastic container registry for easy to track and deploy. We can persist our trained model to file servers such as Gemfury or Amazon S3. Code sits in Github to manage effectively, to version, collaborate and host the code. All these steps with CI/CD pipeline. Finally we deploy the applications to either managed cloud platforms like Heroku or our own configured cloud infrastructure such as AWS Elastic container service. With this systems in place we can server our predictions via REST API as requests come in from clients.
Clarity on architecture and trade offs are important before embarking into complex development project, particularly with ml systems.
Train by batch, predict on the fly.

Breakdown: Training Phase (done offline/ train by batch)

Training data: applications will be responsible for loading, processing and giving access to the training data(could be pulling data from multiple SQL or NoSQL databases, HDFS, or make API calls), perform pre processing steps to get to the format required by scikit-learn, tensorflow or another ml framework.
Feature Extractor
There will be Applications and scripts to create features, extract features(can be simple scripts or entire models itself)
Model Builder
This includes serializing and persisting models, versioning them, making sure they are in the format suitable for deployment. In python context, this would involve in packaging with a set of py files.
In Java or Scala, we might export to an mlib bundle/jar files.
All three steps will be structured into a pipeline perhaps with scikit learn or when performance is important then Apache Spark. These piplelines will be run by CI/CD platforms to automate the work.
The output is a trained model, which can be easily deployed via REST API.
Breakdown: Prediction Phase
The model is now deployed to production to give results in real time. Requests are sent to our REST API, cleaned and prepared by the preprocessing and feature extraction code. We should mirror the code used in training as close as possible.
Prediction are given by our loaded model.
Our API can do both single and bulk predictions, where bulk predictions are subject to performance tuning and throttling.

Everything when put together, we can offline and online part of the system.

It is important to see where the code overlaps. For eg: Feature extractor(extracting features of the input given by clients to REST API as same features decided on the train time) code.
There are other components required to make the entire system running apart from application.
Entire System Diagram

Top left is the application part with examples of tools and frameworks. CI/CD pipeline sits in the middle. Our application code can be converted into docker images and stored in image registery such as docker hub or AWS Elastic container registry for easy to track and deploy. We can persist our trained model to file servers such as Gemfury or Amazon S3. Code sits in Github to manage effectively, to version, collaborate and host the code. All these steps with CI/CD pipeline. Finally we deploy the applications to either managed cloud platforms like Heroku or our own configured cloud infrastructure such as AWS Elastic container service. With this systems in place we can server our predictions via REST API as requests come in from clients.
Clarity on architecture and trade offs are important before embarking into complex development project, particularly with ml systems.
No comments:
Post a Comment